Kernel journey with bpftrace
背景
前几天同事和我聊起 calico 的一些实现原理,他给了我一个脚本让我试玩一下如何通过 linux 下的 veth 设备使得在单独的 network namespace 可以与 host 进行通信。意外的是,在我的笔记本上整个方案没有正确地工作。由于缺乏相关的文档支持,所以我通过使用 bpftrace 配合阅读内核的源码,终于搞明白了是什么原因导致的,借此机会记录下来展示下 bpftrace 及一些相关工具的基本用法。
问题描述
通过执行下面的脚本,我们将会创建一个新的 network namepsace: ns0 ,以及一对 veth 设备 v-ns0 和 v-ns0-peer。我们将 v-ns0 放入 ns0 中,将 v-ns0-peer 留在 host 中,通过开启 v-ns0-peer 的 proxy_arp 功能我们应当能看到 v-ns0-peer 设备会用自己的 MAC 地址响应 v-ns0 设备发出的 ARP 请求。如果进一步设置相关的转发和路由规则 ns0 中的进程将可以顺畅地与其他机器上的容器进行通信。
1 |
|
我面临的主要问题是在我的笔记本上执行完上面的脚本后, v-ns0-peer 设备的 proxy_arp 功能并没有生效,通过使用 wireshark 在 v-ns0-peer 上抓包同时执行 ip netns exec ns0 ping 192.168.1.1 ,可以明显看到只有对于 ns0 中的默认网关 169.254.0.1 的 ARP 请求却没有任何的 ARP 应答。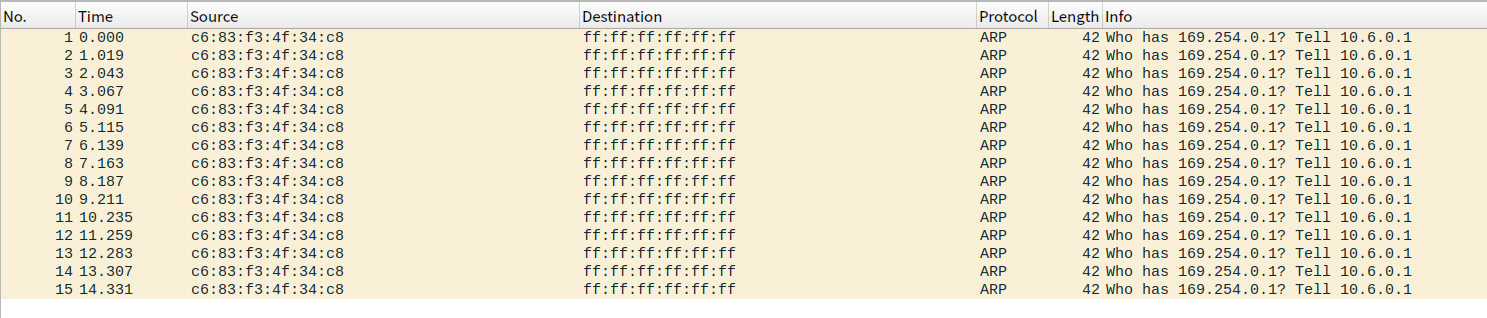
问题分析
设备 v-ns0-peer 的 proxy_arp 功能没有正确工作,我一开始的推测是需要开启某些设置,可能是安全策略相关的。所以一开始在 google 上找了一圈资料,但是没有发现什么特别有帮助的,于是考虑跟踪下内核的代码,看看是什么条件没有符合。直接阅读内核代码的方式来分析难度比较大,因此我选择一边阅读一边使用 trace 工具快速确定内核的执行路径,这里我选择使用的工具是 bpftrace 。
工具准备
我的笔记本是 ubuntu 20.04 的操作系统,其他操作系统下工具的安装和准备应该是类似的。
- 获取当前内核的源代码。执行
apt-get source linux-image-unsigned-$(uname -r)即可。 - 获取当前内核的 debug info 。添加源 ddebs.ubuntu.com 后执行
apt-get install linux-image-$(uname -r)-dbgsym即可。 - 安装 bpftrace 以及 bcc 。执行
apt-get install bpftrace bpfcc-tools linux-headers-$(uname -r)即可。
定位内核代码
我们的目标是找出 proxy_arp 功能为什么不工作,处理 ARP 请求的代码在 net/ipv4/arp.c 中的 arp_process 函数中。通过大致阅读该函数,我们可以迅速发现与 proxy_arp 相关的代码段应该如下 813 行附近。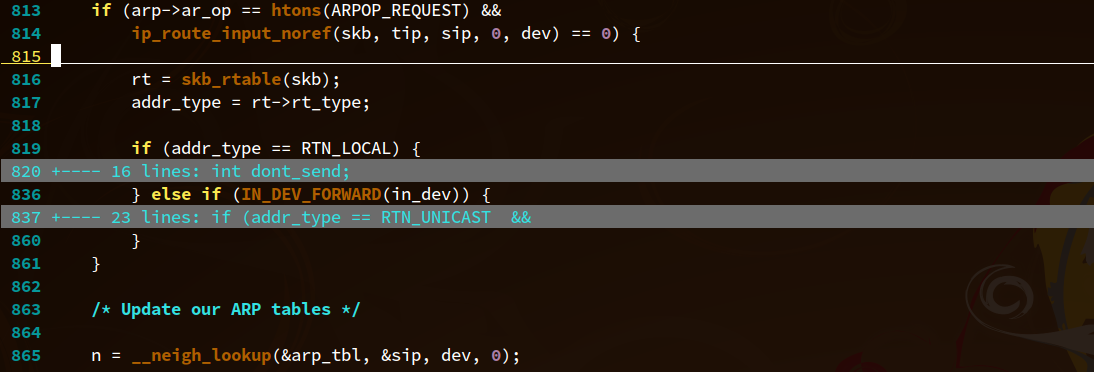
trace 内核
我们的 ARP 请求在设备 v-ns0-peer 上被收到以后内核执行到 813 行,检查 arp->ar_op 肯定是 ARPOP_REQUEST ,所以我们第一需要确定函数 ip_route_input_noref 的返回值。我们使用 bpftrace 来完成这项工作,通过执行 bpftrace -e 'kretprobe:ip_route_input_noref { printf("pid %d. ret: %d\n", pid, retval); }' 我们可以得到 ip_route_input_noref 每次调用的返回值。
开始 trace 以后,我们还没有在 ns0 中执行任何操作的情况下,已经能看到一些输出了:
这个显然是机器上处理其他的 ARP 请求的时候执行的,为了排除这些干扰,我将笔记本的网络断开了,再重新开始 trace ,并执行 ip netns exec ns0 ping 192.168.1.1 来触发 ARP 请求。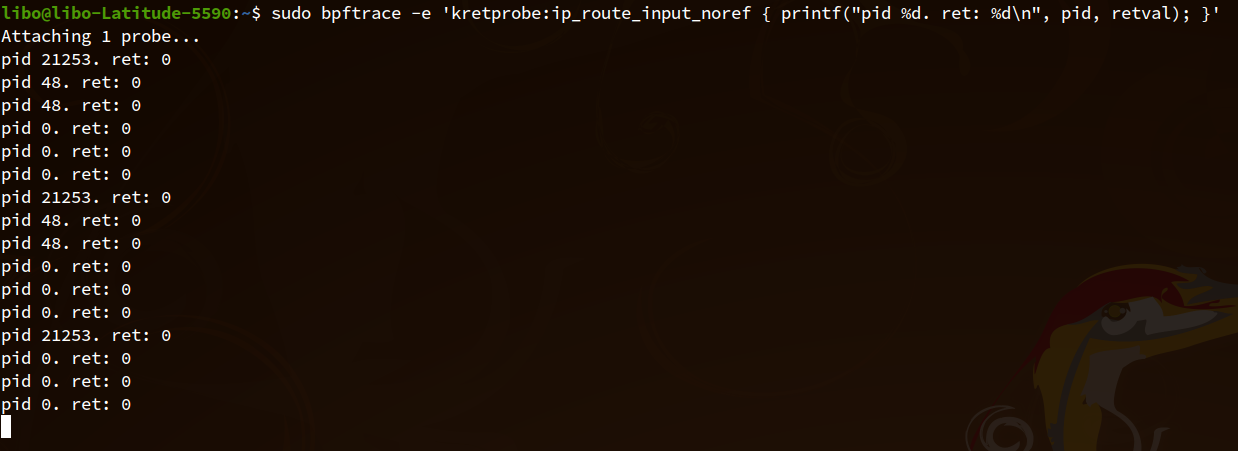
可以看到有很多输出,有的 PID 是 ping ,有的 PID 是 0 ,所有的返回值都是 0。所以我们可以肯定代码肯定进入了816行,接下来是两个分支,819行和836行。因为函数 skb_rtable 被内联了,我们无法使用 bpftrace 去 trace 该函数。为了确认代码的执行路径,我们可以利用 bpftrace 的 kprobe 支持 function offset 这个特点来打点。
反汇编内核
为了知道819和837两个分支的代码相对于函数 arp_process 的偏移,我们使用 gdb 反汇编 gdb -q /usr/lib/debug/boot/vmlinux-$(uname -r) --ex 'disassemble arp_process' ,然后迅速滚动到有函数 ip_route_input_noref 的调用的附近: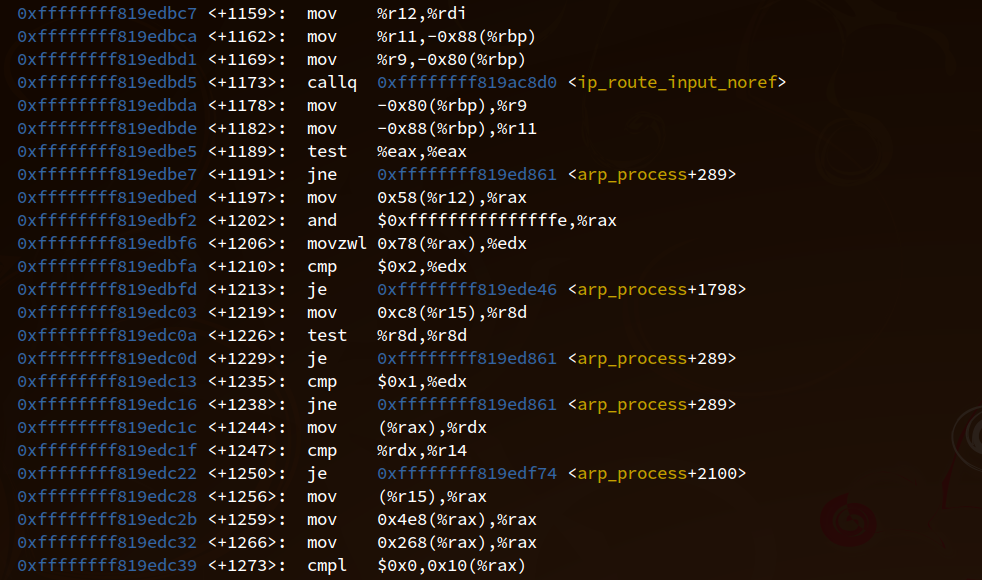
从图中可以看到,函数 ip_route_input_noref 的调用在 +1173 的位置,接下来 +1191 判断其返回值是否为0,不为0就跳转到 arp_process+289 的位置,我们可以使用 addr2line 来确认下对应的是代码中的什么位置。执行 addr2line -e /usr/lib/debug/boot/vmlinux-$(uname-r) 0xffffffff819ed861 得到结果 linux-5.4.0/include/net/neighbour.h:516 。阅读代码发现是函数 __neigh_lookup 的实现,该函数其实是在 865 行调用的,被内联了。
因为我们上面 trace 知道 ip_route_input_noref 返回是0,所以代码执行应该是进入了816行,也就是顺着 +1197 继续执行。+1197 从内存读取一个值将低位抹掉作为地址去加载一个值,通过读代码我们知道是函数 skb_rtable 的内容,接着+1210的判断其实就是我们的819行的判断,读代码可以知道 RTN_LOCAL 的值是 2 ,RTN_UNICAST 的值是 1 。为了确定代码是否进入了820行,我们可以在+1219埋点,可惜的是我的笔记本上安装的 bpftrace 在编译的时候没有开启 ALLOW_UNSAFE_PROBE 所以当我在笔记本上执行 bpftrace -e 'kprobe:arp_process+1219 { printf("executed\n"); } ' 的时候报错:
手工使用 bcc
bpftrace 不支持,我们可以使用 bcc 直接写程序来 trace 内核,代码非常简单:
1 | # -*- coding: utf-8 -*- |
运行起来我们的 bcc 程序,执行 ping ,然后我们发现,+1219 是有执行到的,那么说明 addr_type 的值不是 RTN_LOCAL 。所以代码将会执行到836行的判断 IN_DEV_FORWARD(in_dev) ,直接看汇编代码,我们很容易看出关键是看+1229的 je 指令,如果发生跳转就说明没有进入837行。所以我们继续 trace +1235 即可知道,执行 ping ,我们发现 +1235 没有执行到!说明 IN_DEV_FORWARD(in_dev) 的判断没成功,我们进入代码库搜索发现这是一个宏,主要干的事是检查设备的 forwarding 选项是否开启。我们执行 cat /proc/sys/net/ipv4/conf/v-ns0-peer/forwarding 可以看到结果是0,所以我们将其修改为1后继续 trace 。现在代码顺利执行到了 +1235 ,但是抓包依然没有看到 ARP 应答。
我们继续看汇编,+1235 和 +1238 的判断对应代码中837行的第一个条件,测试 addr_type 是否是 RTN_UNICAST ,我们继续 trace +1244 来验证下这个条件判断是否成功。执行 ping ,我们发现这个判断失败了,所以代码执行跳到了后面,于是 proxy_arp 没有正确工作。
稍微阅读下代码,我们可以知道 addr_type 是使用我们 ARP 请求里面的目的 IP 地址查路由表后得到的讯息,这里的逻辑只是要确保我们的 IP 地址是单播地址。而我们查讯的地址 169.254.0.1 是 link-local 地址,肯定是单播地址,因此这个行为就比较奇怪了。进一步思考,结合 wikipedia 中对 proxy_arp 的一段描述:
The proxy is aware of the location of the traffic’s destination, and offers its own MAC address as the (ostensibly final) destination.
我猜测是因为断网状态下我的笔记本不知道如何到达 169.254.0.1 ,执行 ip route get 169.254.0.1 报错:RTNETLINK answers: Network is unreachable 。打开笔记本网络继续测试,首先 ip route get 169.254.0.1 正确返回了,然后我们退回去最开始去 trace ip_route_input_noref ,为了让干扰尽量少,我关闭了笔记本上大部分程序。开启 trace 后执行 ping 结果发现 ip_route_input_noref 居然返回了非0值:-18 。
深入 ip_route_input_noref
阅读内核代码,ip_route_input_noref 的实现在 net/ipv4/route.c 中,一个简化的调用链路是 ip_route_input_noref -> ip_route_input_rcu -> ip_route_input_slow 。其中函数 ip_route_input_slow 比较复杂,而我们的目的只是简单找到返回 -18 的原因,因此我们可以跟踪产生返回值的地方,除开大部分常值不符合我们的期望外,第一个可能产生 -18 的地方是对于函数 fib_validate_source 的调用。执行命令 bpftrace -e 'kretprobe:fib_validate_source { printf("pid %d. ret: %d\n", pid, retval); }' 并开始 ping ,我们非常幸运,果然这个函数返回了 -18 !
追随 fib_validate_source
函数 fib_validate_source 的实现在 net/ipv4/fib_frontend.c 里面,代码很短,可能产生 -18 的返回值的地方是函数 __fib_validate_source ,进入函数 __fib_validate_source 查看,很显眼看到末尾的 return -EXDEV ,简单用个 C 程序验证就发现 errno EXDEV 正好是 18!阅读代码发现导致返回 EXDEV 的原因是参数 rpf 非0,而该参数是上层函数 fib_validate_source 传进来的,值是这样得到的:int r = secpath_exists(skb) ? 0 : IN_DEV_RPFILTER(idev); 。所以说明是 secpath_exists(skb) 返回了0,然后 IN_DEV_RPFILTER 返回了非0值。但是我们一开始的脚本里面明明是有这样一句的 echo 0 > /proc/sys/net/ipv4/conf/$VETH-peer/rp_filter ,所以这里就比较奇怪了。
到这里我们知道了方向但是依然不知道最终的原因是什么,我们继续看看 IN_DEV_RPFILTER 的实现有什么奇怪的地方。在 include/linux/inetdevice.h 中我们找到了这个宏的定义为: #define IN_DEV_RPFILTER(in_dev) IN_DEV_MAXCONF((in_dev), RP_FILTER) ,我们继续看 IN_DEV_MAXCONF 的定义:
1 |
|
啊哈!原来这个是取全局的值和设备的值中的较大者。执行 cat /proc/sys/net/ipv4/conf/all/rp_filter 发现该值为 2,将其修改为0后再进行测试, ARP 应答正确出现!